思维上大事拆解成小事,行动上小事积累成大事
从小事做起
-
重大问题
是什么
最近学习python爬虫时,在爬取今日头条图片时,自己卡在进入图组后下载图片,在卡者几天的情况下,我依然按自己的思路去解决,结果自己依然没有解决,当今天看了原作者的github项目时,突然发现因为今日头条接口改变了,他的项目也更新了,而自己却依然用老方法去撞。
怎么样
我感觉很崩溃
浪费时间
-
爬虫简单学习
1.原理
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
流程
用户获取网络数据的方式:
方式1:浏览器提交请求—>下载网页代码—>解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
1、发起请求
2、获取响应内容
3、解析内容
4、保存数据
-
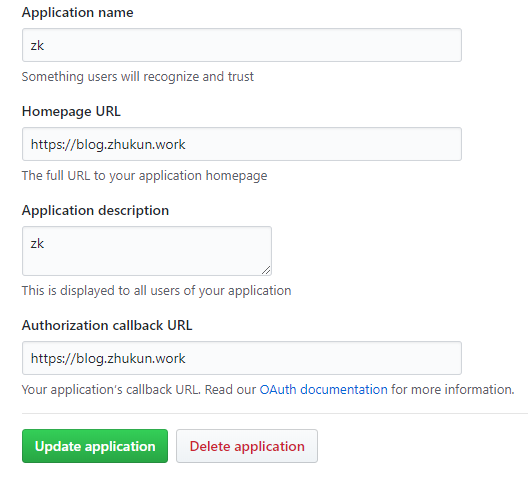
gitment为jekyll博客添加评论功能
申请Github OAuth Application:
Github头像下拉菜单 > Settings > 左边Developer settings下的OAuth Application > Register a new application,填写相关信息: